
프로젝트의 목적
- 이 프로젝트는 한국어 신어를 월 단위로 수집·분석하고, 그 사용 양상을 관측하는 데 목적이 있습니다.
-
더 나아가 미국방언학회, Oxford English Dictionary 등에서 수행하고 있는 것처럼, 정량적·정성적 분석 결과를 바탕으로 ‘올해의 신어(Word of the Year)’를 선정하고자 합니다.
-
한국어 신어에 대한 국가 주도의 조사는 「신어의 조사와 연구」(국립국어연구원 1994) 이후 총 22회 수행되었으며, 2020년부터는 연세대학교 남길임 교수 연구 팀과 경북대학교 언어정보연구센터에서 매년 신어사전을 편찬하고 있습니다(남길임 외 2021~2025). 이 프로젝트 역시 1994년 이후 이어져 온 한국어 신어 조사 방법론에 기반하고 있습니다.
-
사전을 만드는 일은 생각보다 훨씬 더 고된 작업입니다. 18세기 영국의 시인이자 평론가였던 새뮤얼 존슨은 인류가 사전 편찬자를 ‘학문의 제자’가 아닌 ‘학문의 노예’로 대한다고 말하며 스스로를 ‘겸손한 노역자(humble drudge)’라 칭한 뒤, 6명의 조수와 함께 8년 10개월에 걸쳐 4만 2천여 개의 표제어로 구성된 영어 사전을 완성했습니다. 그마저도 서문에서 “언어를 고정하려는 시도는 바람을 채찍질하는 것과 같다.”라고 고백해야 했습니다(Johnson 1755/2004). 270년이 지난 지금도 사정은 크게 다르지 않아서, 사전, 특히 신어사전 편찬에는 막대한 시간과 비용, 인력이 필요합니다.
- 이에 본 프로젝트에서는 한국어 어휘 체계의 역동성을 관측하기 위해 ‘말뭉치’, ‘거대 언어 모델’, ‘사전학 전문가’의 방법론적 삼각측량(methodological triangulation)에 기반한 신어 수집·분석 파이프라인을 설계·개발했습니다. 신어 조사의 생산성과 효율성, 정확성을 높이면서도, 말뭉치 기반 언어 연구의 재현 가능성과 반증 가능성을 확보하는 것이 목표입니다(안진산 2026a).
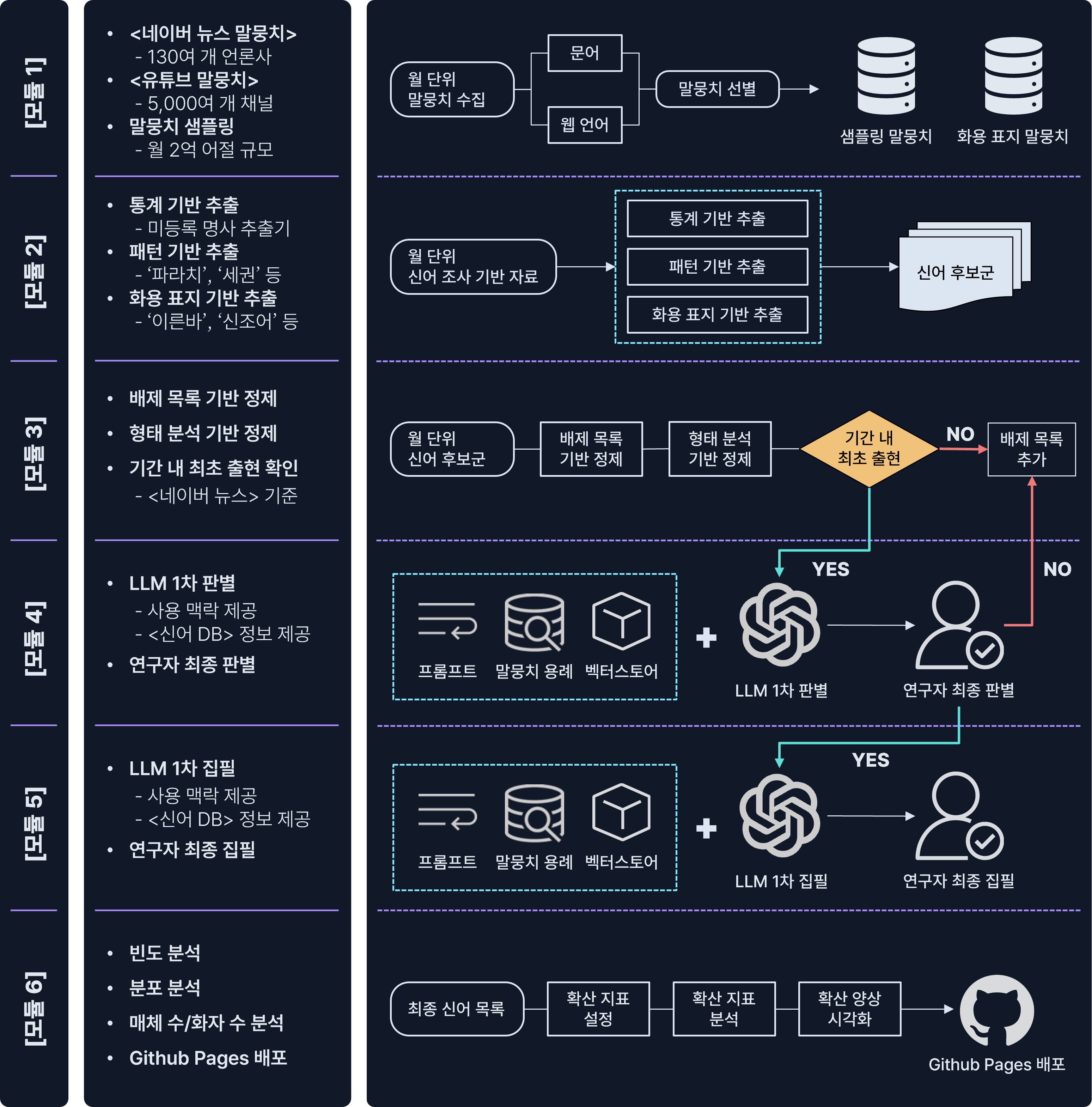
- LLM 보조 사전 편찬을 둘러싼 기대와 우려는 모두 일정 부분 사실입니다. 한쪽에서는 LLM의 생산성과 효율성을 기대하는 반면, 다른 한쪽에서는 환각 현상 등의 기술적 한계, 비결정성과 비윤리성 등을 근거로 우려를 표하고 있습니다.
첫 번째 질문, LLM이 신어를 판별할 수 있을까요?
- 남길임·안진산·이수진(2025)에서는 LLM을 활용하여 『신어 2023』의 ‘기존 신어 목록(325개)’을 ‘확장 신어 목록(368개)’으로 약 13% 확장한 바 있습니다. 인간이 놓친 43개의 신어를 LLM을 활용하여 추가로 찾아낸 셈이죠. 물론 LLM도 완벽하지는 않아서, 신어를 비신어로 잘못 판단하거나 그 반대의 실수를 저지르기도 합니다.
| 세부 작업 내용 | 후보군 | TP | FN | FP | TN | F1 |
|---|---|---|---|---|---|---|
| 1차 신어 판별(인간) | 6,301 | 91 | 43 | 0 | 6,167 | 0.80899 |
| 1차 신어 판별(GPT-4o) | 6,301 | 85 | 49 | 288 | 5,879 | 0.33516 |
| 최종 신어 판별(인간) | - | 134 | - | - | - | - |
| 계열어 등 추가 수집 | - | 368 (+234) | - | - | - | - |
두 번째 질문, LLM이 신어를 집필할 수 있을까요?
- 안진산(2026b)에서는 이 질문에 대한 실험 결과를 제시합니다.
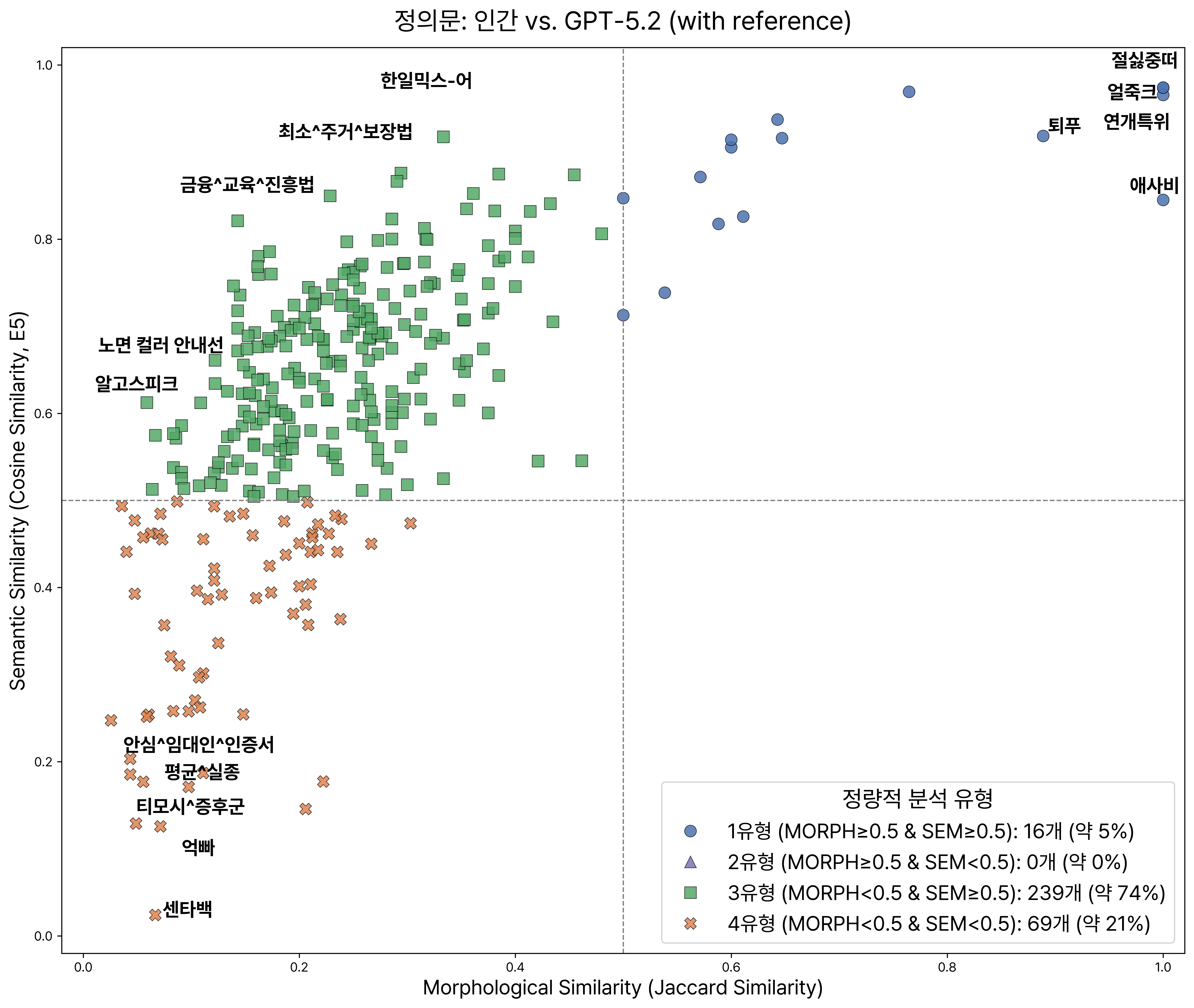
- 오른쪽 상단의 1유형은 인간과 LLM의 뜻풀이가 형태적으로도, 의미적으로도 거의 일치하는 항목입니다. ‘절싫중떠(‘절이 싫으면 중이 떠나야지’를 줄여 이르는 말)’가 대표적입니다. 전체의 70% 이상을 차지하는 왼쪽 상단의 3유형은 표현은 다르지만 말하고자 하는 바는 통하는 경우입니다. 예컨대 ‘한일믹스어’에 대해 인간은 “한국어와 일본어를 섞은 말”로 간결하게 풀이한 반면, LLM은 “한국어와 일본어의 어휘나 표현을 섞어 만든 말”처럼 부가 정보를 덧붙이는 경향이 있습니다. 물론, LLM은 ‘깊털(기프티콘 털어 먹기)’을 “‘깊은 털이’를 줄여 이르는 말”로 풀이하는 등 형식의 삭감, 삭감 후 결합 등 복합적인 형태론적 기제가 적용된 단어에서는 중의성 해소에 어려움을 겪기도 합니다. 왼쪽 하단의 4유형은 LLM의 한계가 뚜렷하게 드러나는 경우입니다. ‘티모시 증후군(뇌의 신경 세포 칼슘 채널 결함으로 인한 희귀 질환)’의 인명 ‘티모시(Timothy)’를 동명의 배우 ‘티모시 샬라메(Timothee Chalamet)’로 착각해 엉뚱한 뜻풀이(특정 인물이나 대상의 말투나 행동, 옷차림 따위를 지나치게 따라 하며 그 인물과 비슷해지려는 심리 상태)를 만들어 낸 것이 대표적인 환각 사례입니다.
결국 핵심 질문은 이것입니다.
- 4유형의 오류를 어떻게 3유형, 나아가 1유형으로 끌어올릴 것인가?
- 답은 신뢰할 수 있는 참조 자료에 있습니다. 신어의 출현 맥락이 담긴 고품질 텍스트 데이터와 기존 <신어 DB>를 함께 제공하면, LLM의 형태적 유사도는 +0.044, 의미적 유사도는 +0.081 유의미하게 상승합니다(p<.001). 하지만 참조 자료만으로 모든 오류가 사라지는 것은 아닙니다. ‘티모시 샬라메’와 같은 실수는 여전히 일어날 수 있으니까요. 그렇기 때문에 사전 편찬자가 이 파이프라인의 최종 관문 앞에 서 있는 것입니다.
-
이 파이프라인은 2025년 1월부터 월 단위로 가동되고 있으며, 매달 새롭게 출현하는 한국어 신어를 수집·분석하여 그 결과를 이 저장소를 통해 공개합니다.
- 혹시 새로운 단어를 발견하셨나요?
- 아래 링크를 통해 제보해 주시면, 해당 신어의 사용 양상을 관측하여 이곳에 공개하도록 하겠습니다.
문의: 경북대학교 언어정보연구센터 안진산 (san@knu.ac.kr)
참고문헌
- 안진산(2026a), 「실시간 신어 추출 파이프라인의 설계와 검증」, 『한글』 제87권 제1호.
- 안진산(2026b), 「거대언어모델을 활용한 신어 집필의 가능성과 쟁점」, 『한말연구』 제67권.
- 남길임·안진산·이수진(2025), 「말뭉치, LLMs, 인간 전문가의 협업을 통한 한국어 신어의 탐지」, 『한국어학』 108호.
- 남길임 외(2025), 『신어 2024』, 한국문화사.
- 남길임 외(2024), 『신어 2023』, 한국문화사.
- 남길임 외(2023), 『신어 2022』, 한국문화사.
- 남길임 외(2022), 『신어 2021』, 한국문화사.
- 남길임 외(2021), 『신어 2020』, 한국문화사.
- Johnson, S. (1755/2004). Preface to a dictionary of the English language., Project Gutenberg
주요 기여자
-
남길임
연세대학교 국어국문학과 교수
nki@yonsei.ac.kr -
이수진
경북대학교 국어국문학과 외래교수 | 언어정보연구센터 선임연구원
sjmano27@knu.ac.kr -
안진산
경북대학교 국어국문학과 외래교수 | 언어정보연구센터 연구원
san@knu.ac.kr -
2020년 이후 한국어 신어 조사는 연세대학교 남길임 교수 연구 팀과 경북대학교 언어정보연구센터에서 수행하였습니다.
경북대학교 언어정보연구센터 홈페이지
지금까지 기여해 주신 분들
다음 전문가 분들이 2020년 이후 한국어 신어 조사에 기여해 주셨습니다.
- 송현주(경북대학교 국어교육과 교수)
- 최 준(전남대학교 국어국문학과 교수)
- 현영희(경북대학교 국어국문학과 외래교수)
- 서은영(경북대학교 국어국문학과 외래교수)
- 백미경(경북대학교 국어국문학과 외래교수)
- 강범일(연세대학교 언어정보연구원 연구교수)
- 고예린(전남대학교 국어국문학과 박사과정)
- 성민규(연세대학교 국어국문학과 박사과정)
- 정희윤(NHN 연구원)
- 김해은(국립국어원 연구원)
- 이 준(연세대학교 국어국문학과 석사과정)
- 남궁설(연세대학교 국어국문학과 석사과정)
모든 기여자 여러분께 깊이 감사드립니다. 🙇♂️